Data processing
PIONEER has standardise and integrate existing ‘big data’ from quality multidisciplinary data sources into a single innovative and comprehensive data platform that consists of the most relevant prostate cancer clinical trials and registries, large epidemiological cohorts, electronic health records, and real-world data from different European and non-European patient populations.
Data elements include:
- Demographics
- Epidemiological data
- Diagnosis & monitoring data
- Imaging & lab results
- Treatments
- Outcomes
- Quality of life
- Genomics data
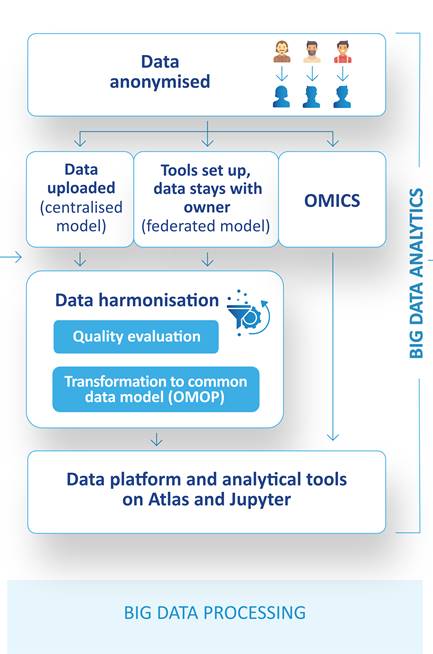
PIONEER operates with two data access models – a central and federated model:
- In the central data sharing model, a copy of the e-identified data is transferred to PIONEER, converted and stored in a central data warehouse for research.
- In the federated model, data owners standardise their own data sets and set up analytical tools within their own data environment and make it available upon request.
In the centralised model, data will be included through conversion of population-based registries and epidemiological research data to a OMOP (Observational Medical Outcomes Partnership) common data model to allow for the systematic analysis of disparate observational databases. PIONEER will also provide a central OMICs analysis platform for cohort and clinical trial data,
Finally, the PIONEER Big Data Platform will provide not only access to data, but also analytical tools (ATLAS, R) in a single innovative data platform, leveraging two existing data platforms, tranSMART and OHDSI, developed in previous IMI projects.
Data protection
Within PIONEER we have chosen to work with data which is not personally identifiable i.e. the data has been redacted to ensure sufficient anonymity such that the identification of the person to whom the data relates simply could not be done without such an unreasonable amount of effort as would make such identification virtually impossible. As a result of this anonymization process the data within PIONEER’s Big Data Platform is not classified as personal data and as such our use of the data complies with all applicable data protection laws at the EU level, falling outside the scope of the General Data Protection Regulation (GDPR), without impacting the clinical relevance of the data.
PIONEER is achieving this by using two database models:
- Federated; and
- Centralised
In the Federated Database Model, the data does not leave its original site, but is interrogated remotely, with PIONEER bringing the analysis to the data. This essentially means that the data remains anonymous to the researches accessing the federated database. Data from a variety of sources is effectively temporarily “linked” in order to address specific queries. The individual data providers retain ownership and control of their data and allow interrogation only against approved requests. This model has been successfully used by other IMI Projects such as EMIF-AD.
For the Centralised Database Model, data physically moves from the data provider to the centralised PIONEER server. To achieve this PIONEER uses two key de-identification methods. The first is the total removal of any direct identifiers (such as patient, name, number, photographs or other images which could allow identification). This process is known as “suppression”.
However, there are also types of information which would not, on their own, be sufficient to allow the identification of a data subject, but when taken in combination may have the capacity to do so, these are known as quasi-identifiers. Examples of these include dates, geographic or regional location, demographic data (such as race and ethnicity), socio-economic data, anthropometric data, sensitive information, medical data, adverse events, and disease characteristics. However, unlike direct identifiers, quasi-identifiers are useful for data analysis. Given the fact that suppressing these data would entail the loss of scientific knowledge in the results of the research studies conducted in PIONEER, quasi-identifiers are addressed by the masking method of “generalisation”.
Generalisation consists of substituting the values of a given attribute with less specific values, or on diluting the attributes of data subjects by modifying the respective scales or order of magnitude. If the value is a categorical value, it may be changed to another categorical value denoting a broader concept of the original categorical value. For example, “male” and “female” can be generalised to “person”. If the value is numeric, it may be changed to a range of values. For example, the granularity of individual rates of birth can be lowered by generalising them into a range of dates or grouped by month or year. Other numerical attributes (e.g. age, salaries, weight, height, or the dose of a medicine) can be generalised by banding.
By using the Federated Database Model and applying the de-facto anonymization process to data entering the Centralised Database, PIONEER will not be processing personal data and therefore complies with data protection law and does not require specific permits, consents or authorisations with regard to the Project.
PIONEER further emphasises good legal, regulatory and ethical practice by use of a data privacy policy binding on its members and by the use of data sharing agreements which contain protective obligations such as an undertaking not to attempt to re-identify data and for any restrictions on the use of a particular dataset to be honoured.

